Artificial Intelligence and Machine Learning Hardware Solutions: Edge AI Design



Deploying AI at the edge means rethinking compute, memory, and data movement together, rather than scaling down a cloud system. This shift has made edge AI a system-level design problem where a disciplined Hardware Design Service plays a central role.
Through most of the last decade, the cloud-first pipeline held up reasonably well. Sensor data moved upstream, inference ran in a centralized infrastructure, and results returned to the device. The model began to break as applications demanded lower latency, tighter data control, and consistent response times. Vision systems in manufacturing, predictive maintenance platforms, and driver assistance features all exposed the limits of relying on remote computing.
That pressure has shifted inference toward the edge, bringing hardware design decisions to the forefront.
Many teams approach edge AI design by focusing on processor selection. In practice, that decision follows broader architectural choices. Effective Hardware Design treats the system as a complete pipeline rather than a set of independent blocks.
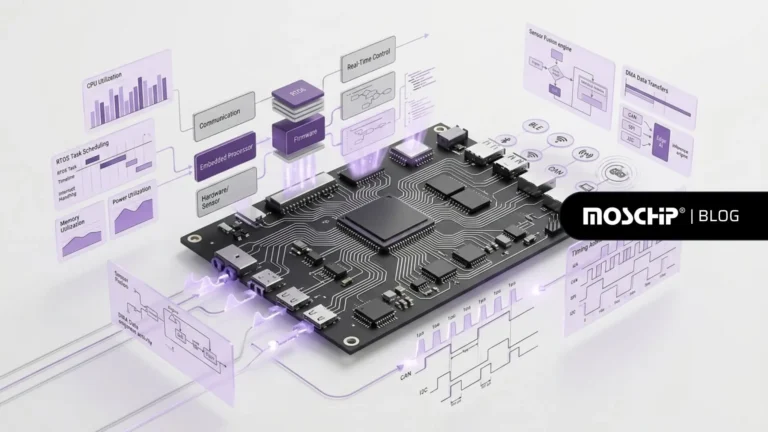
The chain begins with sensor and signal acquisition, moves through ISP and DSP preprocessing, into the compute fabric handling inference, and then into memory hierarchy decisions such as on-chip SRAM versus external memory. Connectivity and power management complete the system.
Each layer affects the others. A model that depends heavily on external memory access can saturate bandwidth before the compute is fully utilized. Similarly, smaller on-chip buffers increase memory traffic and impact overall efficiency. These interactions require system-level planning from the beginning.
Edge AI Hardware Stack
Edge AI systems operate within tightly bounded constraints. Addressing them together is a core part of Hardware Design Services, not a sequence of independent optimizations.
Thermal behavior often becomes a defining constraint, especially in environments without active cooling. The system must sustain operation within varying ambient conditions, which makes workload scheduling and partitioning part of the hardware design itself.
The choice between CPU, GPU, NPU, FPGA, and ASIC depends on the workload characteristics and processing requirements, and is then shaped by system constraints such as low power, latency, and form factor. These considerations also vary across use cases, where differences in data patterns, execution behavior, and system priorities influence the final architecture. Structured Hardware Design Services help align these options with actual workload needs.
Comparing hardware options across key constraints
Most production systems combine several of these elements. The design challenge shifts toward partitioning workloads and managing data movement so that transfers do not dominate system behavior.
In most edge AI programs, model development and hardware design do not begin together. Models are typically trained on server-class infrastructure, while hardware constraints come into focus during deployment. The issue is not the separation itself, but how late those constraints are introduced. Structured hardware design helps bring alignment before integration becomes difficult.
Quantization to lower precision is usually required for deployment, but its impact varies across models and workloads. It is generally validated in stages, after an initial model baseline is established. Techniques such as pruning, which removes less significant weights, and sparsity, where many values become zero, can reduce compute requirements, though their effectiveness depends on whether the target hardware can utilize those patterns.
What matters in practice is the timing of interaction between model and hardware considerations. Once a model is established, it is profiled against hardware constraints such as memory limits, execution patterns, and latency requirements. Adjustments then follow through iterative refinement.
Hardware-aware model design, in this context, becomes a process of tuning rather than upfront definition. Layer configurations, operator choices, and memory access patterns are adjusted based on observed behavior. Models that produce irregular memory access or exceed on-chip buffer capacity still led to performance issues, but these are addressed through successive iterations.
The focus remains on introducing hardware constraints early enough to guide model evolution, without requiring model development and hardware design to proceed in a tightly synchronized manner.
A recurring pattern in edge AI systems is the data movement, rather than compute, that becomes the limiting factor. Addressing this is a key responsibility within Hardware Design.
External memory access introduces both latency and energy overhead. When weights or activations cannot remain on-chip, repeated transfers reduce efficiency. This makes local buffer sizing and data locality central to system performance.
Elements such as DMA configuration, cache hierarchy, and interconnect bandwidth are often less visible during early design stages, yet they determine whether performance targets are achieved in practice.
Several architectural directions are shaping the future of edge AI, and hardware design is central to evaluating their relevance. Designs such as modular integration of sensing, compute, and memory (chiplet-based designs) enable flexible system composition while maintaining close coupling between components. And Hardware designed for defined workloads delivers better efficiency than general-purpose accelerators when execution patterns are well understood. The broader trend points towards tighter integration between sensing, processing, and memory. Reducing the distance between data generation and computation improves both latency and efficiency.
To sum up, Edge AI hardware design requires a system-level approach where compute, memory, and data movement are considered together. The challenges are not isolated to individual components but emerge from their interaction.
At MosChip, this translates into a design-first approach that prioritized architecture, data flow, and integration from the outset. Our hardware design services focus on aligning system requirements with practical implementation, ensuring that performance, latency, and efficiency targets are met within real deployment conditions. Also, the company’s deep understanding of memory hierarchies, interconnect design, computing, power-aware architectures, and AI expertise enables balanced systems and edge devices.

Pradeep Kumar Chinthala, holds an M.Tech (VLSI & Embedded Systems) and serves as the Director of Engineering – Systems Design at MosChip Technologies, boasts over two decades of experience in embedded systems design. His expertise lies in architecting comprehensive platform solutions, encompassing intricate pre-silicon FPGA-based platforms, as well as post-silicon evaluation & Characterisation boards and Embedded products. Pradeep has played a pivotal role in enhancing the efficiency and reliability of embedded systems, effectively bridging the gap between hardware and software.

The shift towards Edge AI is moving faster than the hardware it runs on. For engineering leaders, the challenge has shifted from…

Checkout counters have evolved from mechanical cash registers to barcode scanners and then to self-service kiosks…
Modern embedded systems are expected to operate with predictable timing, continuous reliability, and near….

The development of processors is changing quickly. Historically, improvements have been achieved primarily through…

Edge computing appeared as a transformative approach for handling data closer to its source, minimizing latency, reducing bandwidth usage, and…

Imagine a world where devices depend on a centralized architecture for connectivity and operations. In this scenario, all data collected…

How can manufacturers transform fragmented operational data into real-time intelligence...

Industrial machines are evolving from systems that simply report their status to system…

The demand for high-bandwidth communication is increasing…