Streamlining Bug Lifecycle Management with Intelligent Automation

Bug life cycle management is a vital process in software development, encompassing every step from defect identification to resolution and closure. As software systems grow increasingly complex, traditional methods of defect management often struggle to keep pace with the scale and speed required in modern development cycles. Intelligent automation addresses these challenges by introducing smart, data-driven workflows that optimize each stage of the bug life cycle. From automatically triaging defects to prioritizing critical issues and identifying patterns in recurring failures, automation tools enable teams to handle large volumes of defects with greater efficiency and precision.
Automation is everywhere, playing a significant role in improving efficiency and accuracy in the quality management cycle. Automation is widely used in areas such as test management, execution, and reporting. However, defect reporting and management rely heavily on human intervention for critical tasks, as they often require inspection and judgment. Despite this, defect management during large regression cycles can be time-consuming and full of errors. Various stages of defect management can be automated to address these challenges, including defect reporting, linking defects to actual failures, checking for existing reported defects before filing new ones, automatically closing defects upon resolution, and reopening defects when similar failures recur. By incorporating intelligent automation, organizations can significantly reduce manual effort, improve accuracy, and streamline the entire bug life cycle management process.
For any product’s regression testing, bug life cycle management is a crucial aspect. If not handled properly, the product may end up with open bugs—either missed or unverified—that can persist in the released version. These unresolved issues can lead to compromised quality and a suboptimal user experience. Maintaining detailed bug information throughout the product lifecycle enables faster identification and resolution of issues, significantly reducing turnaround time. In large-scale regression testing, proper failure reporting is essential to ensure accuracy, avoid duplication of similar bugs, and promptly notify the development team of newly identified failures. Without structured management, this process can be time-consuming and prone to human errors, hampering the overall efficiency of the testing process.
Efficient bug life cycle management in regression testing not only improves the quality of the final product but also fosters seamless collaboration between testing and development teams. It ensures that every identified bug is tracked from discovery to closure, creating accountability and minimizing the risk of unresolved issues slipping through the cracks. Moreover, it provides valuable insights into recurring failure patterns, helping teams to proactively address underlying problems in the system. By automating this process with advanced tools, organizations can enhance traceability, scalability, and overall productivity, making bug management a cornerstone of successful regression testing strategies.
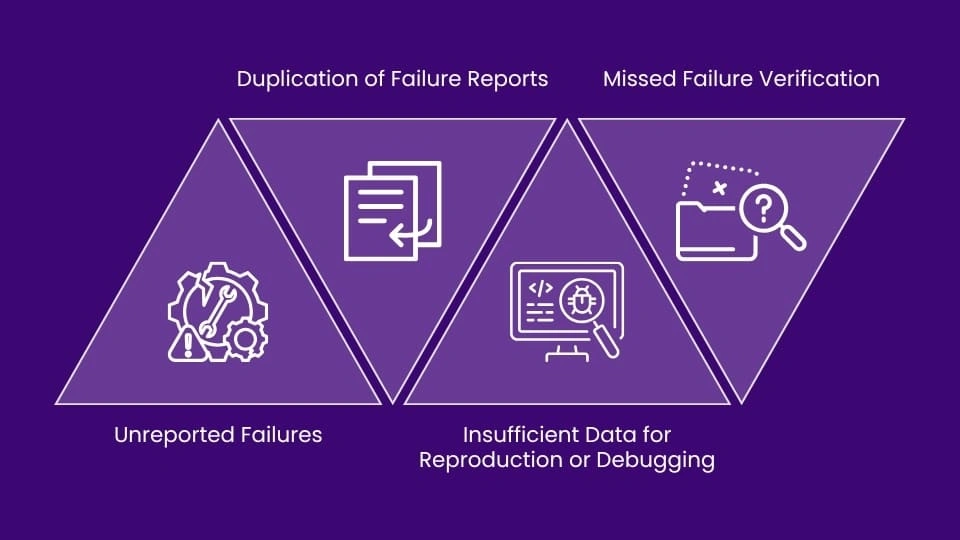
Manual bug life cycle management faces several challenges such as human errors, inefficiency, and lack of scalability, which can negatively impact the overall development and testing process. Errors in documenting bugs, prioritizing them, or assigning them to the correct teams may lead to overlooked or unresolved issues. Tracking and updating bugs manually is time-consuming, particularly in large-scale projects, and can delay the process.
Key Issues in Bug Life Cycle Management in Large-Scale Regression with Human Intervention:
Issues in Manual Bug Lifecycle Management
While each of the above aspects may seem small when addressed individually, they can have a significant impact when multiplied in large-scale regression or extensive product testing setups, ultimately affecting the test cycle execution time. Automation can help eliminate or minimize these issues, streamlining the process and improving efficiency.
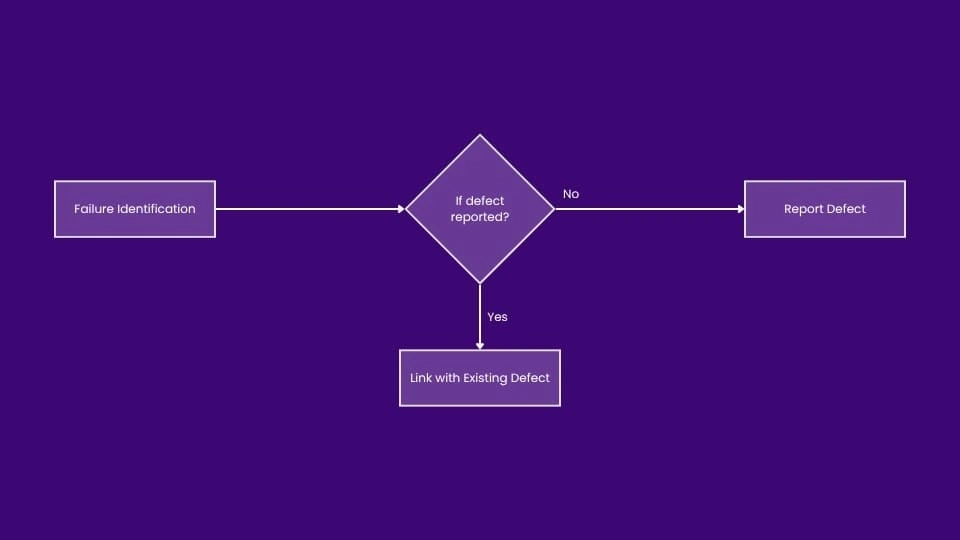
Building an automated mechanism to identify potential failures and error messages at the end of each test execution helps report new failures more quickly.
Automation can help eliminate or minimize all the above issues.
Building an automated mechanism to identify potential failures and error messages at the end of each test execution helps report new failures more quickly. Maintaining a table or central repository based on error messages, failure types, and reported bugs can help identify whether a new failure has already been reported or is genuinely a new bug. The failure reporting script can be enhanced to gather setup data, environment variables, and commands used to reproduce and debug failures more effectively and faster. Additionally, if a previously filed bug passes in the latest test execution, it can be automatically verified or at least reported as passed in the most recent execution.
There are many solutions available for test automation and reporting. For defect management, platforms such as JIRA, OpenProject or integrated defect management mechanisms such as “issues” in GitHub and GitLab are commonly used. However, there is still a void under solution to automate defect identification, reporting, and verification.
Above narrated solution can be implemented in Python, as most code versioning systems, defect management tools, and orchestrators provide Python APIs.
In the end, streamlining bug lifecycle management through intelligent automation is crucial for efficiency, error reduction, and faster software development cycles. Automating key stages like defect identification, reporting, verification, and history management helps organizations to minimize manual work, ensuring smooth workflows. Utilizing tools such as Python APIs and centralized failure repositories, it speeds up debugging, avoids duplication, and enhances traceability. Automation not only tackles manual defect management challenges in large-scale regressions but also fosters collaboration between QA and development teams, leading to higher-quality software with quicker turnaround and improved accuracy. At Moschip, our expertise can enable businesses to fully automate bug lifecycle management as per it’s system-under-test and test environments. This helps to optimize test and development cycle execution time, human resources, and streamline QA processes in large unorganized setups.

All the technology products we use today, from mobile applications to connected cars and industrial controller systems, depend on software as the invisible backbone for functionality…

Automated testing in digital transformation Benefits of automated testing in digital transformation The several benefits of automated testing plays in…

As automotive design rapidly evolves from hardware-centric machines to software-driven ecosystems, ensuring Functional Safety (FuSa) becomes critical to innovation. Software-defined…

The Industrial Internet of Things (IIoT), through distributed systems, autonomous control, and real-time intelligence, has transformed…

The rapid evolution of technology has ushered in new paradigms in software development, particularly in the domain of Test Automation….

Modern software ecosystems are intricately connected, largely thanks to cloud-native architectures, containerization, and microservices…


Know how we have helped our client get more safety rating for their latest auctomobiles launched!