
Model Compression Techniques for Edge AI
Deep learning is growing at a tremendous pace in terms of models and their datasets. In terms of applications, the deep learning market is dominated by image recognition followed by optical character recognition, and facial and object recognition. According to Allied market research, the global deep learning market was valued at$ 6.85 billion in 2020, and it is predicted to reach $ 179.96 billion by 2030, with a CAGR of 39.2% percent from 2021 to 2030. Well, at one point in time it was believed that large and complex models perform better, but now it’s almost a myth. With the evolution of Edge AI, more and more techniques came in to convert a large and complex model into a simple model that can be run on edge and all these techniques combine to perform model compression.
What is Model Compression?
Model Compression is a process of deploying SOTA (state of the art) deep learning models on edge devices that have low computing power and memory without compromising on models’ performance in terms of accuracy, precision, recall, etc. Model Compression broadly reduces two things in the model viz. size and latency. Size reduction focuses on making the model simpler by reducing model parameters, thereby reducing RAM requirements in execution and storage requirements in memory. Latency reduction refers to decreasing the time taken by a model to make a prediction or infer a result. Model size and latency often go together, and most techniques reduce both.
Popular Model Compression Techniques
Pruning
Pruning is the most popular technique for model compression which works by removing redundant and inconsequential parameters. These parameters in a neural network can be connectors, neurons, channels, or even layers. It is popular because it simultaneously decreases models’ size and improves latency.
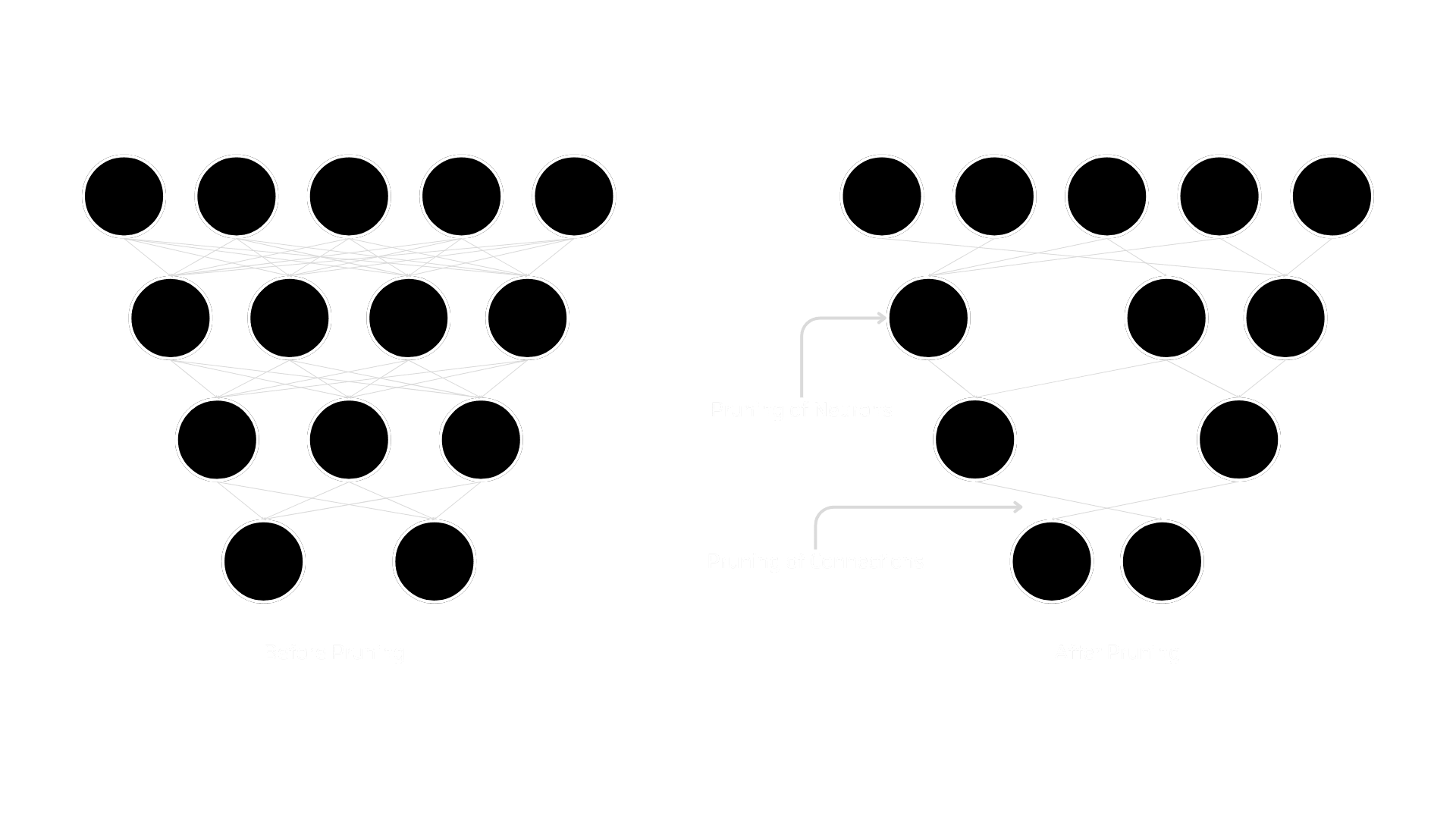
Pruning
Pruning can be done while we train the model or even post-training. There are different types of pruning techniques which are weight/connection pruning, Neuron Pruning, Filter Pruning, and Layer pruning..
Quantization:
As we remove neurons, connections, filters, layers, etc. in pruning to lower the number of weighted parameters, the size of the weights is decreased during quantization. Values from a large set are mapped to values in a smaller set in this process. In comparison to the input network, the output network has a narrower range of values but retains most of the information. For further details on this method, you may read our in-depth article regarding model quantization here.
Knowledge Distillation
In the Knowledge distillation process, we train a complex and large model on a very large dataset. After fine-tuning the large model, it works well on unseen data. Once achieved, this knowledge is transferred to smaller Neural Networks or models. Both, the teacher network (a larger model) and the student network (a smaller model) are used. There exist two aspects here which is, knowledge distillation in which we don’t tweak the teacher model whereas in transfer learning we use the exact model and weight, alter the model to some extent, and adjust it for the related task.
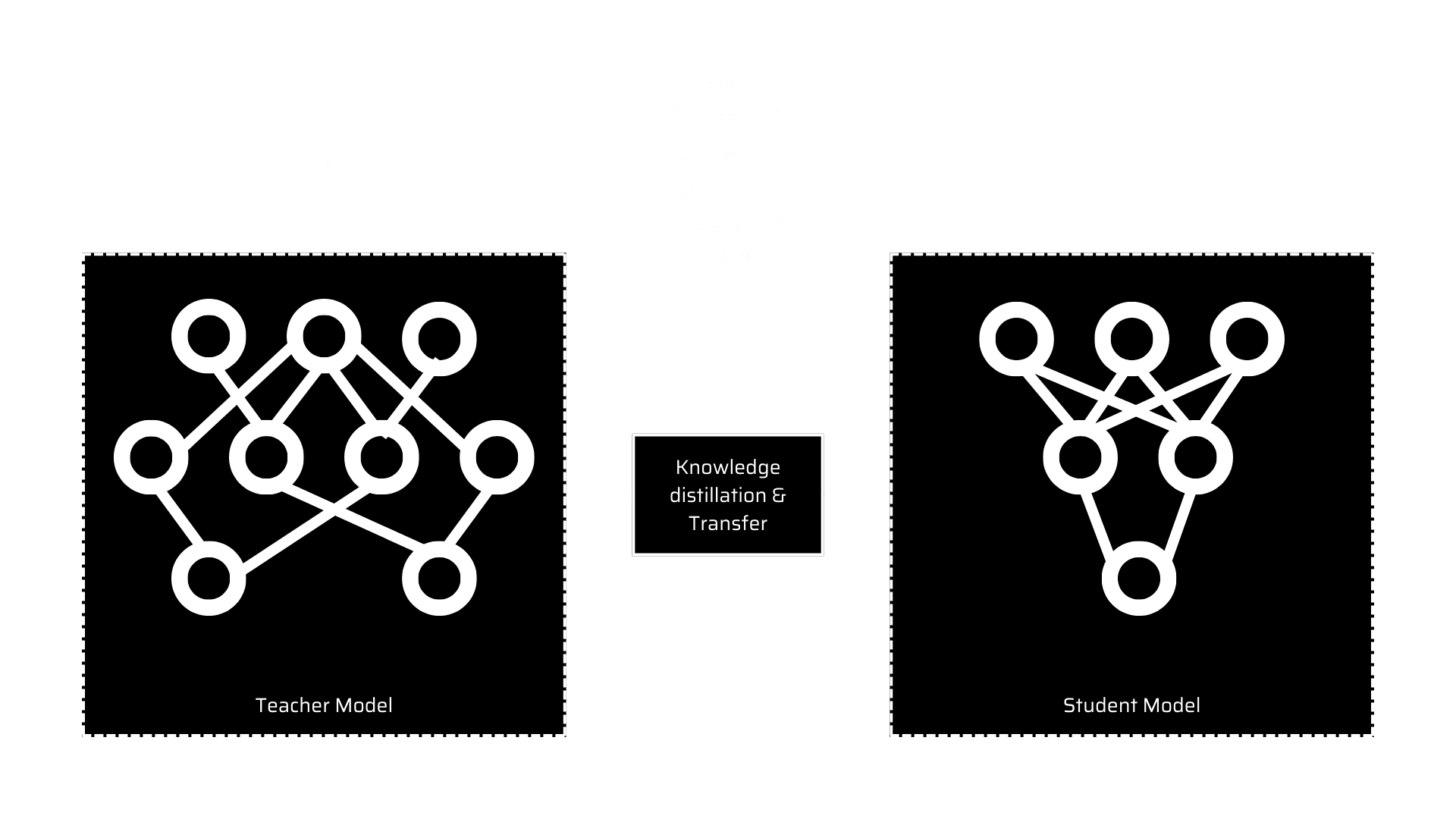
knowledge distillation system
The knowledge, the distillation algorithm, and the teacher-student architecture models are the three main parts of a typical knowledge distillation system, as shown in the diagram above.
Low Matrix Factorization:
Matrices form the bulk of most deep neural architectures. This technique aims to identify redundant parameters by applying matrix or tensor decomposition and making them into smaller matrices. This technique when applied on dense DNN (Deep Neural Networks) decreases the storage requirements and factorization of CNN (Convolutional Neural Network) layers and improves inference time. A weight matrix A with two dimensions and having a rank r can be decomposed into smaller matrices as below.
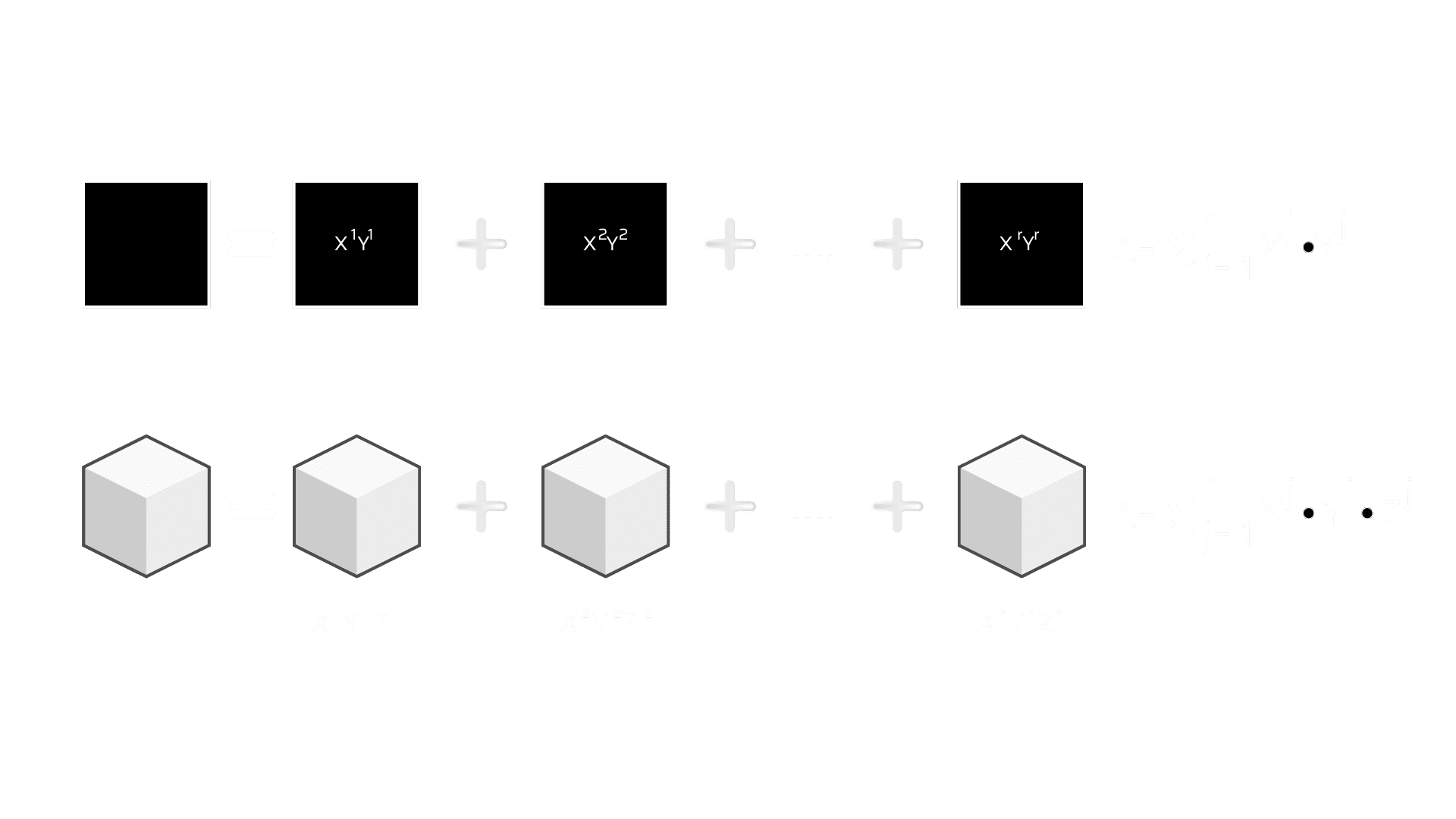
Low Matrix Factorization
Model accuracy and performance highly depend on proper factorization and rank selection. The main challenge in the low-rank factorization process is harder implementation and it is computationally intensive. Overall, factorization of the dense layer matrices results in a smaller model and faster performance when compared to full-rank matrix representation.
Due to Edge AI, model compression strategies have become incredibly important. These methods are complementary to one another and can be used across stages of the entire AI pipeline. Popular frameworks like TensorFlow and Pytorch now include techniques like Pruning and Quantization. Eventually, there will be an increase in the number of techniques used in this area.
At MosChip, we provide AI Engineering and Machine Learning services with expertise on cloud platforms accelerators like Azure, AMD, edge platforms (FPGA, TPU, Controllers), NN compiler for the edge, and tools like Docker, GIT, AWS DeepLens, Jetpack SDK, TensorFlow, TensorFlow Lite, and many more targeted for domains like Multimedia, Industrial IoT, Automotive, Healthcare, Consumer. We collaborate with organizations to develop high-performance cloud-to-edge machine learning solutions like face/gesture recognition, people counting, object/lane detection, weapon detection, food classification, and more across a variety of platforms.
Stay current with the latest MosChip updates via LinkedIn, Twitter, FaceBook, Instagram, and YouTube







