What are the Factors to Consider for AI Model Fine-Tuning?




Today, almost every OEM is racing to bring intelligent, AI-enabled products to the market across automotive, industrial automation, healthcare devices, consumer electronics, and smart building management.
Foundational AI models have made this journey easier because they are already trained on broad patterns and behaviours, helping teams move faster from idea to working prototypes without starting from scratch.
But here’s the catch: a foundational model is not a finished product. Real-world products need accuracy, reliability, and contextual understanding that generic models often cannot provide. Each OEM operates in a unique environment with different sensors, workflows, safety rules, compliance constraints, and customer expectations. Naturally, a one-size-fits-all model struggles to deliver the performance a specialized product requires.
That’s where AI model fine-tuning comes in. It allows engineering teams to adapt a general model using their own device data, real operating conditions, industry terminology, and decision boundaries. This improves accuracy, reduces false alarms and failures, and delivers more predictable behaviour in critical situations while also reducing time-to-market.
AI model fine-tuning bridges the gap between what’s possible and what’s deployable, transforming broad intelligence into precise, OEM-grade intelligence. With that in mind, let’s look at the key factors that influence how well an AI model performs once it’s fine-tuned.
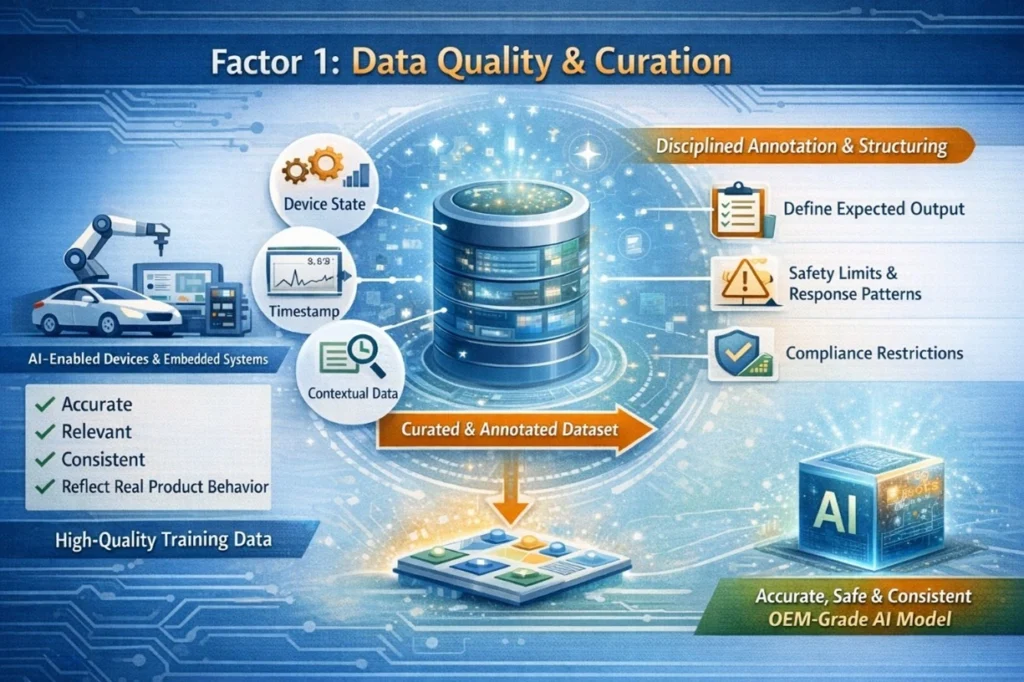
For companies developing AI-enabled embedded systems, successful model fine-tuning begins with one essential element: high-quality, well-curated data. Any data collected must be accurate, relevant, consistent, and reflects actual product behaviour – not just a large volume of data that can be collected. The performance and reliability of AI models, therefore, depend directly on the quality of the training data used during fine-tuning.
Equally significant are disciplined annotation & structuring. Engineering teams must define expected output, safety limits, response patterns, and compliance restrictions to ensure that the model behaves consistently within the specified requirements of the product. Small & well curated datasets that include significant operational conditions, edge cases, and failure modes tend to yield better results than large amounts of generic data.
By using structured metadata (such as device state, timestamp data, and contextual data from the environment) the fine-tuned model creates a better model to understand real-world products & behaviour. This provides an OEM-grade AI system ready for reliable deployment.
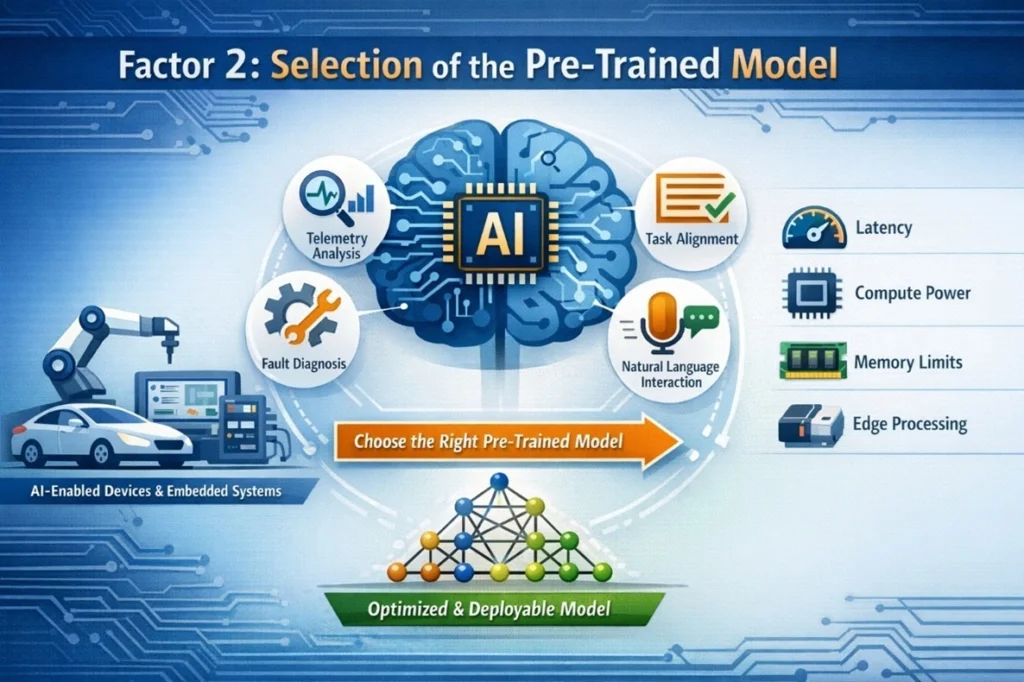
Once a high-quality dataset is ready, the next important step is choosing the right pre-trained AI model for fine-tuning. This decision greatly influences how effectively the AI system adapts to the product’s real operating environment. AI model fine-tuning does not completely change a model’s architecture; it mainly refines the capabilities that already exist. That’s why selecting a model that already aligns with the product’s intended function is so important.
For AI-enabled devices, connected systems, and embedded intelligence, OEMs should begin with task alignment. The model should naturally support what the product needs to do, whether it’s interpreting telemetry data, analyzing sensor signals, diagnosing system faults, or enabling natural language interaction for operators.
Deployment considerations also play a key role. Factors such as latency requirements, available compute power, memory limits, and on-device processing capabilities must be evaluated.
The best outcomes come from models that balance performance with deployability. Lightweight and optimized architectures often perform better in edge environments where resources are limited, making fine-tuning more efficient and practical.
If you have concerns regarding more specific topics related to your LLM selection, such as training alignment, controlling hallucination, and domain adaptation, we encourage you to read through our additional guide regarding “Large Language Models Fine Tuning”.
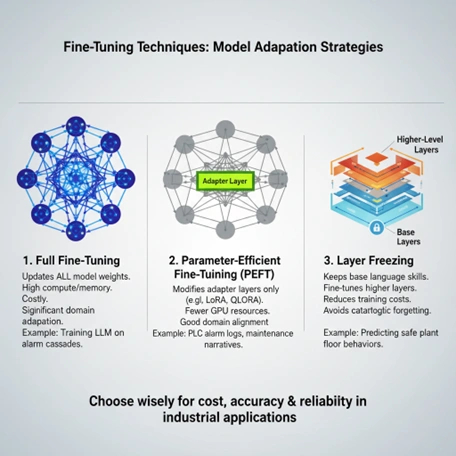
Once the correct base model has been selected, the next step is determining how to fine-tune the model from the PES perspective. The type of fine-tuning method selected will impact the model’s accuracy, cost of training, efficiency of deployment, and long-term reliability once the AI system is utilized within real products or industrial environments.
In this process, all the parameters of the models are updated through training. The complete fine-tuning method should be applied for products where the model will undergo extensive domain adaptation by learning complicated models of industrial activity or diagnostic behaviour of the systems and alarms relating to each other. The other side of full fine-tuning is that due to the amount of computing resources and time, the product would not be feasible for production purposes will have large computing resource requirements and would not be practical for a significant number of production programs.
PEFT (parameter-efficient fine-tuning) enables efficient and effective adaptation of large language models by using either LoRA or QLoRA to modify only the adapter layers, rather than updating the entire model. From the perspective of PES, this method is very beneficial because it reduces the amount of GPU time consumed, reduces the amount of time spent in each training cycle, and continues to allow for good domain alignment based on data related to the product (telemetry logs, maintenance records, operational reports, etc.).
The concept of layer freezing means that the core language capabilities of a base model are not altered during fine-tuning, but rather only the top (upper) layers of the model go through a fine-tuning process. This process also allows engineering teams to lower their overall training costs from the use of this technique while still providing stable, predictable model performance for product deployments.
Using the correct fine-tuning method will help ensure that your AI will continue to grow in an efficient manner and still maintain reliability in real-world products.
After choosing a fine-tuning strategy, the following step would be determining which hyperparameters will control the rate at which the model learns during training. Hyperparameter tuning is essential to ensure the model trains effectively on the product data and produces consistent, reliable results
Among the main hyperparameters are the learning rate, the batch size, and the number of training epochs. The learning rate defines how much the model adjusts parameters during training. If the learning rate is set too high, it could result in an unstable model and missed signal; if it is set too low, it could lead to slow and inefficient training.
The batch size will determine how many training examples are used at once to process, which will affect both the amount of memory used and how quickly the model is trained. Likewise, the number of training epochs (number of times the model has passed through the training dataset) must be carefully determined so as not to overfit to the training data, which will cause the model to memorize the training data but not learn any overall/general features.
PES-based product development, the systematic adjustment and evaluation of these variables guarantees that the AI system will deliver on all three areas: maximum effectiveness, training speed, and reliability when used as a solution in the actual product environment.
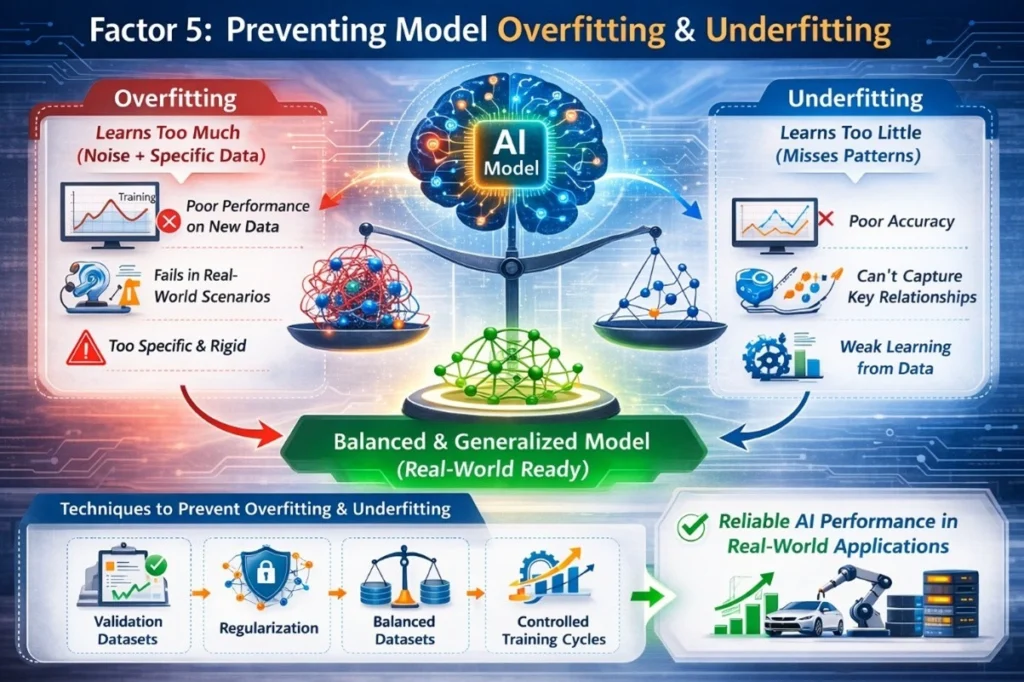
Once you have set the hyperparameters for your AI model, the next most important thing to consider is how well your AI model will generalize (work well) in real-world situations. In the case of Product Engineering Services (PES), one of the main objectives when creating your AI model is to avoid two types of common issues that can occur during training, which are overfitting and underfitting. If either of these two conditions occurs, it can have a direct correlation to how well your AI system will work after it is installed in either a product or industrial setting.
Overfitting occurs when the model learns the training data too closely, including noise or very specific patterns that may not appear in real operational conditions. While the model may perform extremely well during training, it often struggles when exposed to new inputs in production environments, such as unexpected sensor readings or unusual device behaviors.
Underfitting, on the other hand, happens when the model fails to learn enough from the dataset. This usually results in poor accuracy because the model cannot capture important relationships within product data.
To address these challenges, teams often use techniques such as validation datasets, regularization methods, balanced datasets, and controlled training cycles. These techniques are designed to help the model learn meaningful operational features while still being flexible enough to adapt to new situations.
OEM’s can develop AI systems that consistently perform reliably in real-world applications by properly managing overfitting and underfitting.
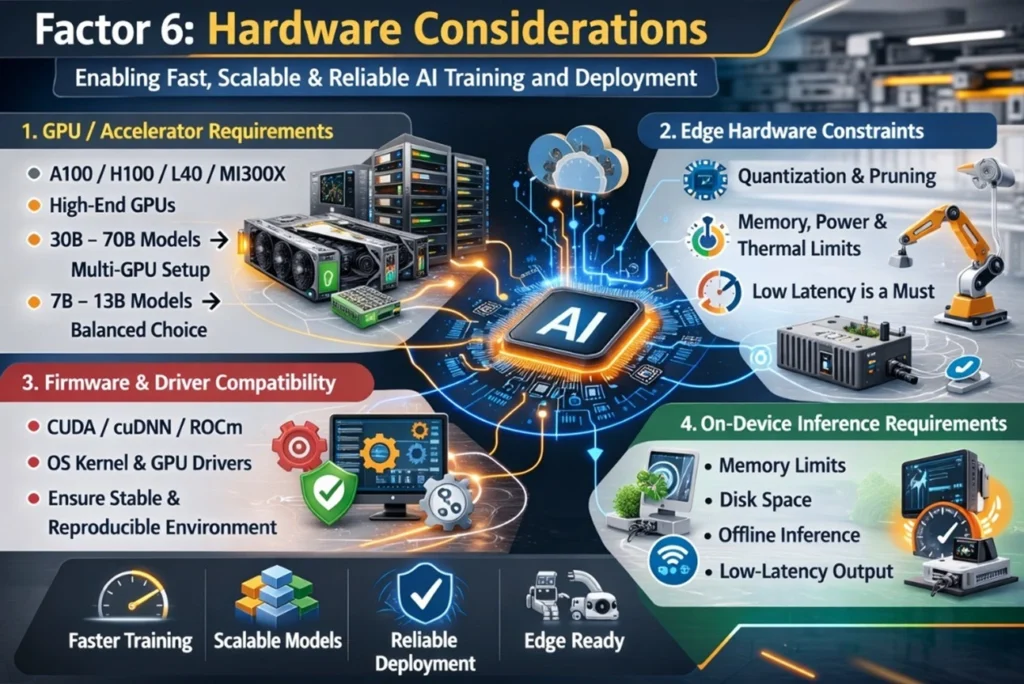
Although fine-tuning can be driven by data/modelling requirements, there are also hardware/software architectural considerations. This is especially critical when models need to run reliably in production environments or on limited industrial devices. The hardware you select plays a crucial role in determining your training speed, the size of the model you can handle, and whether you can deploy it effectively on the factory floor or at the edge.
Choosing suitable compute resources, such as A100/H100, L40, MI300X, or high-end GPUs, significantly impacts training performance. Larger models (30B–70B parameters) require substantial VRAM and often multi-GPU setups. Techniques like tensor parallelism, quantization, or distributed training can help fit models within hardware limits, though they increase engineering complexity. In many enterprise cases, 7B–13B models offer a practical balance between performance and GPU resource requirements.
For edge deployments on industrial gateways or ARM-based devices, models must often be optimized through quantization or pruning to meet memory, power, and thermal limits. Low latency is essential, since operators require immediate responses for diagnostics or decision-making.
Stable training requires compatible firmware, drivers, and software stacks. CUDA/cuDNN (or ROCm), the operating system kernel, and GPU drivers must work together correctly. Incompatibility can cause training failures or slow performance, so maintaining a consistent and reproducible environment is essential.
When deploying models on gateways or mobile devices, memory limits, storage capacity, and offline inference needs influence the model’s size and format. Ensuring reliable, low-latency inference on constrained hardware is key for successful real-world deployment.
Once hardware has been considered, the second factor is assessing computing resources and total project budget estimates with respect to fine-tuning. For PES-type services focused on Product Development, developing AI will need to weigh trade-offs between costs and performance. Large models typically need higher amounts of GPU resources, longer training cycles and higher operating costs than smaller models.
There are several OEM applications out there; however, for each application, companies are focusing on building an efficient model rather than a larger one. As part of this effort, teams should consider costs associated with computing infrastructure, retraining cycles, monitoring, and long-term maintenance.
By aligning compute resources to business goals, organizations can ensure AI fine-tuning strategies produce scalable, production-ready solutions that offer a measurable return on investment (ROI).
After evaluating computational resources and ROI, the next important factor is ensuring security, privacy, and ethical responsibility during AI model fine-tuning. AI systems often rely on sensitive data sources such as device telemetry, diagnostic logs, operational workflows, and proprietary engineering data. Protecting this information is essential for maintaining product integrity and preserving customer trust while deploying AI-driven systems.
Security in AI is about protecting the training data, models, and infrastructure from unauthorized access, data leaks, or tampered models. To obtain protected product intelligence, use secure storage, controlled access practices, and encrypted data pipelines.
Privacy ensures that any user or operational data used in training is anonymized and compliant with regulatory standards, preventing exposure of confidential customer or operational information.
Ethics involves ensuring the AI system behaves responsibly, avoiding biased outputs, unsafe recommendations, or actions that could impact safety in real-world environments.
Together, these practices help OEMs build trustworthy, compliant, and production-ready AI systems.
After tackling issues related to security, privacy, and ethical considerations, the next crucial step is to ensure that the AI model operates reliably during both evaluation and real-world use. From the perspective of Product Engineering Services (PES), this involves both quantitative and qualitative validation.
Metrics like accuracy, F1 score, ROUGE, and BLEU are useful for assessing how effectively the model identifies patterns and produces structured outputs. However, relying solely on these numerical metrics is insufficient.
This is where a human-in-the-loop (HITL) review becomes important. Domain experts, operators, or engineers evaluate the model’s outputs to check for clarity, safety alignment, and practical applicability in real-world product situations.
During deployment, using model monitoring and version control tools is essential to track performance, maintain stability, and enable safe updates.
Overall, robust evaluation and deployment practices play a key role in keeping the fine-tuned AI model reliable, safe, and ready for production over time.
MosChip’s AI engineering capabilities enable AI models to be fine-tuned through scalable machine learning pipeline mechanisms, allowing further customization of the inference model implementations. Further optimizations, including retraining, quantization, and edge deployment, are also possible.
The DigitalSky GenAIoT™ and AgenticSky™ accelerators provide additional capabilities for adapting models, allowing for faster personalisation of the models and improved accuracy while also seamlessly integrating with embedded platforms, cloud-based platforms, and edge-based platforms, enabling the creation of next-gen intelligent products.
To know more about MosChip’s capabilities, drop us a line, and our team will get back to you.

Darshil is a Marketing professional at MosChip creating impactful techno-commercial writeups and conducting extensive market research to promote businesses on various platforms. He has been a passionate marketer for more than four years and is constantly looking for new endeavors to take on. When He’s not working, Darshil can be found reading and playing guitar.

Optical Character Recognition (OCR) technology is essential in transforming data management and operational efficiency in the automotive industry. OCR enables…

The Artificial Intelligence of Things (AIoT) is revolutionizing industries by combining the power of Artificial Intelligence (AI) and the Internet…

The shift towards Edge AI is moving faster than the hardware it runs on. For engineering leaders, the challenge has shifted from…

MosChip’s AgenticSky helps OEMs move beyond “smart” by embedding agentic traits – autonomy, proactivity, adaptability, and trust – into every product…

Predictive maintenance is a key component of the Industrial Internet of Things (IIoT), shifting from reactive fixes and fixed schedules to proactive…

I have always thought that a surveillance system is only as good as its ability to quickly turn vision into timely insights…


Know how we have helped our client get more safety rating for their latest auctomobiles launched!