VisionCore for Smart Public Systems: CCTV Cameras as Agentic Assistants

I have always thought that a surveillance system is only as good as its ability to quickly turn vision into timely insights. Every time I step into a control room of a public parking facility, an industrial site, or even a retail store, I am often struck with the same pattern. Abundant cameras, countless video data, yet when an incident occurs it takes hours to retrieve the right video footage.
If a vehicle goes missing from a parking lot, the process is painfully similar. Surveillance teams will scrub through hours of footage, jump across multiple camera feeds, and manually correlate timelines. Even with AI models in place, the investigation remains fragmented and slow. Getting to the right answer in seconds simply isn’t how today’s systems are designed.
Every second lost makes the process of finding the missing vehicle more difficult. However, the future of security and surveillance doesn’t have to be this painful.
What we really need are not more models or more cameras. What we need is – Agentic AI, a more goal-oriented, adaptable, continuously learning, and autonomous AI system that makes surveillance more autonomous, and delivers exceptional user-experience.
Traditional surveillance systems are built as static pipelines. Video streams are ingested, pre-defined AI models are executed, alerts are triggered, and a human on the other side will interpret and decide.
In real-world public environments, that assumption breaks down quickly. Incidents evolve dynamically, objectives change in real time, and context spans across cameras, locations, and time windows. Fixed pipelines and rule-based orchestration struggle to adapt, leading to delayed responses and operational overload.
Even when advanced computer vision models are deployed, they operate in isolation. Detection, recognition, and tracking remain disconnected capabilities rather than coordinated intelligence.
To address this gap, we need to move to Agentic AI, which introduces intent, reasoning, and autonomous decision making into the surveillance workflows.
At a high level, an agentic AI-based surveillance system separates perception from decision orchestration. Instead of binding object detection, object recognition, and tracking models into fixed pipelines, these capabilities are exposed as modular services and operates with a goal-oriented mindset.
An Agentic AI-based surveillance system operates based on what goal needs to be achieved, reasons about how to achieve it, and autonomously involves the required capabilities. This causes a shift from passive monitoring to active problem-solving.
When an objective is given, in many cases a user-query, the agent decomposes the task into various subtasks. It selects the appropriate models, determines the execution order, and dynamically correlates outputs across data sources. Importantly, outputs are treated as feedback signals rather than terminal results, enabling continuous refinement.
https://youtu.be/co5gkdzzo6c?si=pgh9MyIeoaz26alR
Let’s try to understand this with a practical scenario.
I parked my car outside in a parking lot at a retail store and went inside to get my groceries. I returned over an hour later and my car was missing from the parking lot. A sudden panic set-in as I quickly scanned the entire parking lot but locate my car. I quickly decided to go back into the store and inform the loss-prevention officer in the store. I had to describe the make of the car and where I had parked and at what time.
He asked me to file a complaint with law enforcement and agreed to look at the footage, but it was going to take some time. This irked me quite a bit because I knew I was going to get more anxious as time passed.
Why does it have to take so long? The cameras were right there. The footage was there, yet retrieving procedure was unnecessarily painful.
Now imagine the same moment if the surveillance system had agency.
Instead of filling out forms and waiting for manual review, the loss-prevention officer simply enters a query:
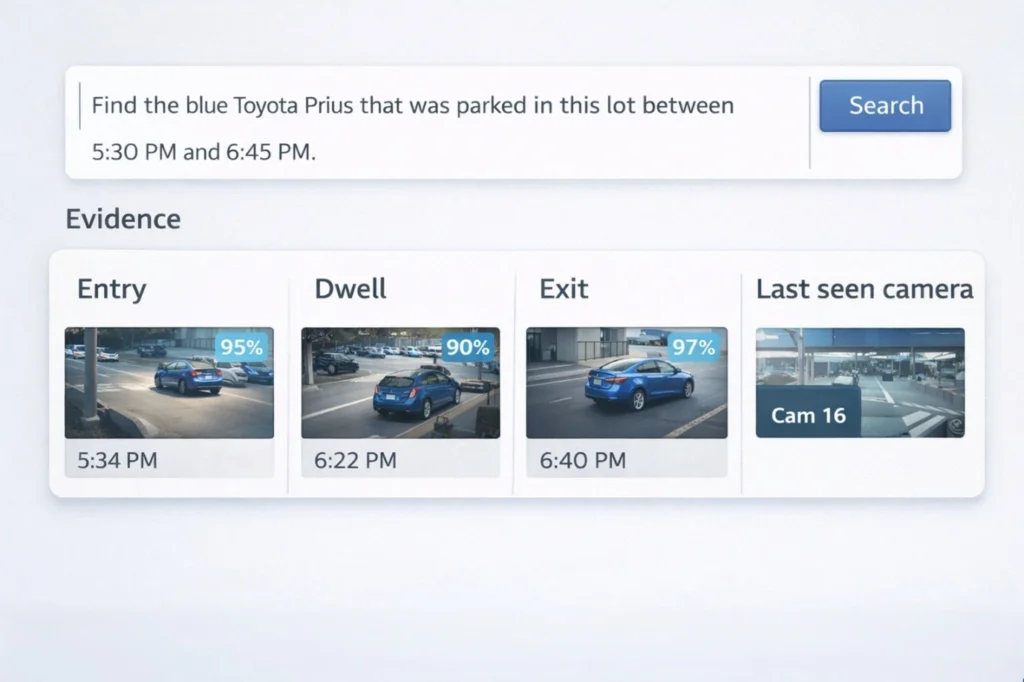
“Find the blue Toyota Prius that was parked in this lot between 5:30 and 6:45 PM.”
From that single instruction, the system takes over. It understands the objective, identifies the relevant cameras, and dynamically activates the right vision capabilities such as vehicle detection, recognition, and cross-camera tracking. It correlates footage across time and space, filters out irrelevant data, and surfaces only what matters.
Within seconds, the exact clips appear. The vehicle entering the lot. The point at which it leaves. The route it takes. No manual scrubbing. No guesswork. Just answers.
That contrast is what agency looks like in practice.
Deploying Agentic AI helps you to address the limitation of fixed pipelines. Conventional surveillance architectures assume that threats and scenarios can be predefined. In reality, security incidents are rarely static or predictable. Agentic systems can reason about evolving situations, dynamically adjust analysis strategies, and coordinate multiple vision capabilities without requiring manual reconfiguration.
The sheer scale, complexity, and the time-critical nature of modern public environment demand systems that can reason, adapt, and act autonomously. What has been missing is a practical, production-ready implementation of these principles.
Agentic AI in public security and surveillance systems cannot be implemented on a single-layer architecture. Agents comprise of large models (such as LLMs, object detection and recognition models, planning models, semantic memory, multi-step tools) which are computationally intensive and need multiple layers to run them effectively.
In public security and surveillance, the agent is not just running an inference, it is coordinating a dynamic workflow across cameras, time windows, and model outputs. These stacks require high compute, bandwidth, and memory, while you can only run low-power models on the edge.
That’s why agentic AI requires a hybrid architecture- across edge, near edge , and Cloud.
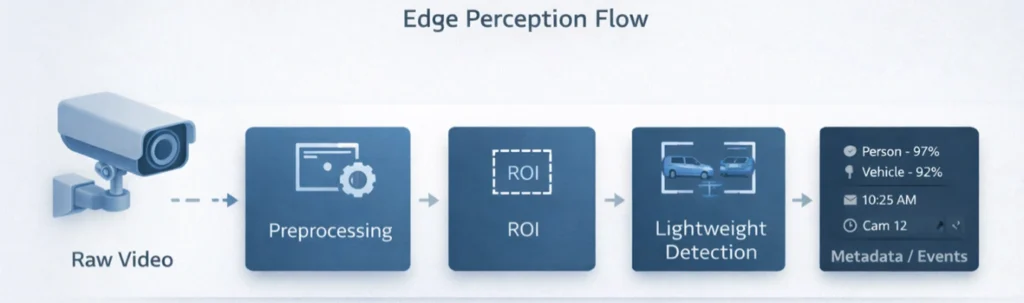
Edge Layer: Video is created at the edge, and that is where time-critical perception must begin. Cameras generate high-volume, high-frequency data, making it challenging to continuously transmit raw streams upstream for centralized processing.
In an agentic surveillance deployment, the camera layer acts as the first perception tier.
Since cameras operate under strict constraints (power, thermal envelope, memory, and compute availability), the workloads running on-camera must be lightweight, always-on, and optimized for real-time responsiveness.
At the camera layer, the system typically executes:
In other words, the camera does not attempt to perform deep multi-model reasoning. Instead, it converts raw video into structured perception signals, events and metadata that can be transmitted efficiently to higher layers.
This approach reduces upstream bandwidth consumption while enabling immediate detection and response at the source. It also ensures the system remains functional during intermittent connectivity, cameras continue to detect, timestamp, and buffer events locally, allowing downstream intelligence to reconstruct and correlate incidents once connectivity and compute resources are available.
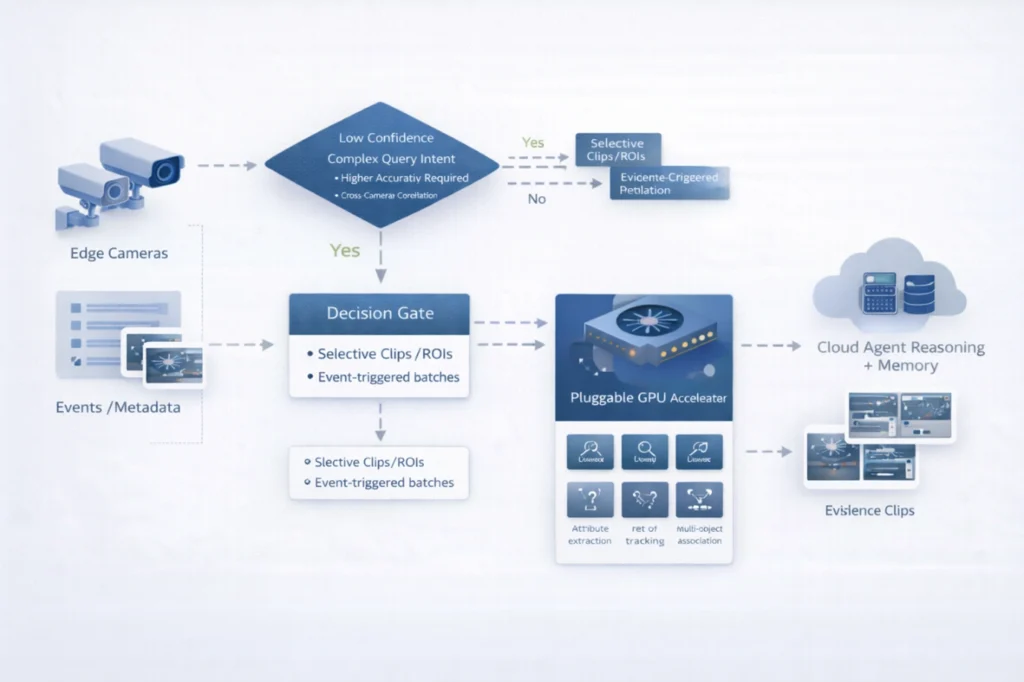
Near edge with pluggable GPU (optional): While the camera layer provides real-time perception and structured metadata, it is not designed to run computationally heavy models continuously. Cameras are constrained by power and thermal limits, and even AI-enabled cameras typically run compact, quantized models with limited throughput.
This is where a near edge layer becomes valuable as an optional acceleration tier that can be introduced when deployments require higher accuracy, deeper feature extraction, or cross-camera correlation with low latency.
Rather than treating GPU compute as an always-on requirement, agentic surveillance architectures use it selectively. The near edge layer can be activated based on incident complexity, query intent, and confidence thresholds allowing the system to scale precision without scaling cost linearly across every camera.
In practice, this GPU layer runs higher-fidelity vision workloads such as:
Technically, this layer functions as the compute bridge between the edge perception tier and centralized agent reasoning. It processes either:
This reduces bandwidth pressure while still enabling workflows close to the data source.
From an agentic AI standpoint, the near edge layer is also the system’s execution accelerator. When a query such as “Find the missing blue Prius” is issued, Agentic AI can decide whether the situation requires deeper inference such as attribute extraction, vehicle ReID, or multi-camera tracking, and dynamically invoke GPU pipelines only for the most probable camera/time segments.
This optionality is important. Many deployments can start with camera-level perception and cloud reasoning, and then introduce GPU acceleration only where required, such as large parking lots, transit hubs, or high-security zones ensuring the architecture remains scalable, cost-efficient, and upgradeable.
Agents on the Cloud:
Agentic surveillance is not just about detecting objects in a frame. It is about resolving an objective by interpreting intent, forming an execution plan, coordinating tools/models, correlating multi-camera evidence, and converging on an answer with high confidence.
That requires statefulness, memory, and global awareness that cannot be reliably maintained at the camera or local acceleration tiers.
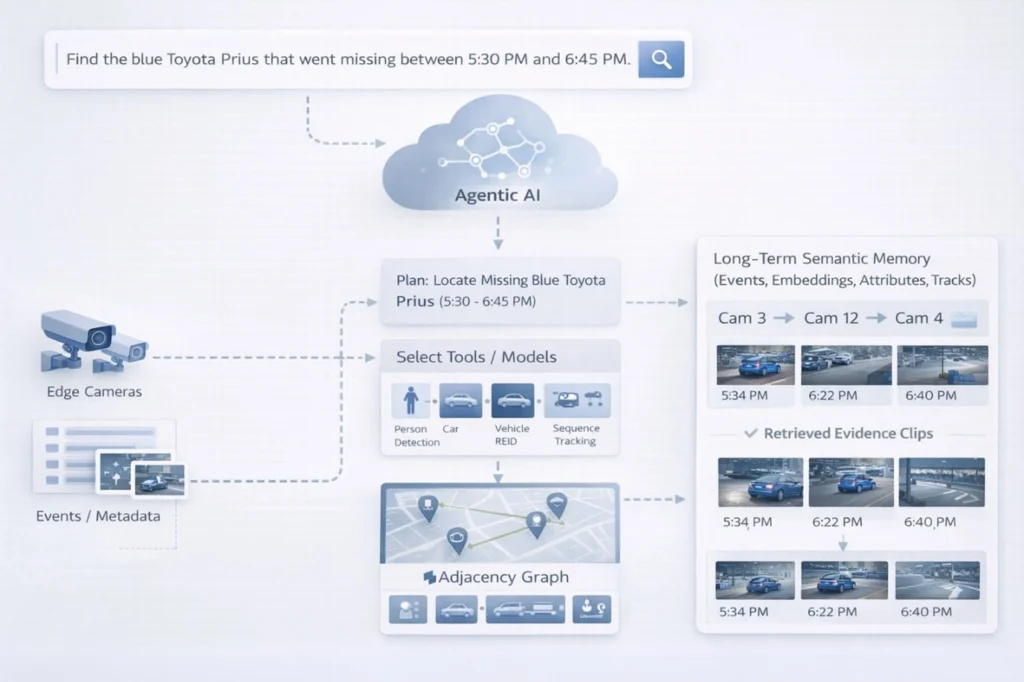
Lets revisit the missing blue Prius scenario. When the query is entered
“Find the blue Toyota Prius that went missing between 5:30 PM and 6:45 PM”, the system must do far more than trigger just a detection model. It must:
To execute such workflows efficiently, the cloud layer provides foundational capabilities that enable agency.
Public surveillance incidents rarely stay within a single camera feed. Vehicles move across zones, blind spots, and multiple timelines. That’s why Agentic AI must live in the cloud, where it can maintain global context using a camera topology graph (coverage overlap, adjacency, handoff paths) and long-horizon incident timelines.
The cloud also provides semantic memory (events, embeddings, attributes, tracks) for fast retrieval via attribute queries and ReID similarity search. Combined with governance and orchestration, it enables intent-driven incident resolution turning video from “footage to scan” into knowledge to query.
Building an agentic surveillance product is not just about deploying vision models. It requires stitching together camera ingestion, edge perception signals, accelerated inference, cloud reasoning, memory, orchestration, and governance. This integration overhead is where most product teams generally lose time.
AgenticSky by MosChip addresses this by providing an accelerator suite that shortens development cycles and reduces the engineering effort (40% reduction in efforts and aids faster time to market) required to move from prototype to production, so teams spend less time building agents from scratch and work more and fine-tuning and deploying.
Within AgenticSky, VisionCore is the accelerator designed specifically for cameras and vision-driven surveillance systems. It operationalizes agentic surveillance by connecting three layers into one workflow: on-camera perception (events + metadata), optional pluggable GPU acceleration (high-fidelity detection, ReID, attribute extraction), and cloud-hosted Agentic AI (intent understanding, planning, semantic memory, orchestration).
The result is intent-driven incident resolution, where a query like finding a missing vehicle triggers the right models, the right feeds, and the right evidence retrieval automatically, accelerating not only investigations, but also product development and deployment readiness.
Wrapping Up
MosChip is a one stop shop solution provider for Product Engineering Services, covering hardware and systems, device software, digital engineering, and AI engineering backed with accelerators such as DigitalSky GenAIoT (for rapid IoT enablement) and AgenticSky, which accelerates product development.
To know how we can help you in your agentic AI product journey, drop us an email and we will get in touch with you.

Smishad Thomas is a Technical Marketing Manager at MosChip. He has over 13 years of experience in technology marketing, branding, and content leadership. He has a keen interest in product engineering and loves developing convincing stories that translates technical innovations into clear, engaging messaging that resonates with business audiences

In recent years, voice technology has steadily increased in popularity, from voice control in vehicles to smart speakers in homes….

In today’s fast-paced and interconnected world, the supply chain landscape is undergoing a significant transformation driven by integrating advanced technologies….

A Machine Learning (ML) pipeline is used to assist in the automation of machine learning processes. They work by allowing…

For several years, industries have used traditional AI/ML systems that could classify, predict, and automate, but only with the limits of the data they were taught…

MosChip’s AgenticSky helps OEMs move beyond “smart” by embedding agentic traits – autonomy, proactivity, adaptability, and trust – into every product…
Today’s wearables sense and notify while tomorrow’s wearables reason and adapt. Agentic AI enables a layered intelligence model where sensing, near-edge reasoning, and cloud-based agents work together to deliver proactive, personalized outcomes. This marks the transition from threshold-driven tracking to continuous, context-aware companionship…


Know how we have helped our client get more safety rating for their latest auctomobiles launched!