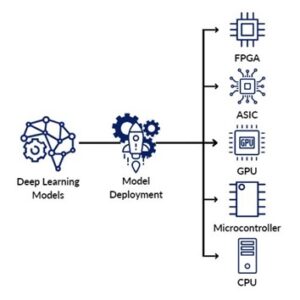
Embedded platforms have revolutionized the way we interact with technology in our daily lives. These deep learning algorithm-equipped platforms have created an endless number of opportunities by facilitating the use of intelligent applications, autonomous systems, and smart devices. It is imperative to implement deep learning algorithms on embedded platforms. It entails tuning and modifying deep learning models to function well on embedded systems with limited resources, like CPUs, FPGAs, and microcontrollers. To lower the model size and computational requirements without compromising performance, this deployment process frequently calls for the use of model compression, quantization, and other techniques.
The embedded systems market is predicted to grow at a rapid rate worldwide and reach USD 170.04 billion in 2023. Precedence Research survey indicates that it will probably keep growing, with estimates putting it at around USD 258.6 billion by 2032. For the years 2023 to 2032, a Compound Annual Growth Rate (CAGR) of about 4.77% is projected. The market analysis yields several important insights. With 51% of the revenue share overall in 2022, North America was the leading region, followed by Asia Pacific with a sizable share of 24%. Regarding hardware platforms, the microprocessor segment accounted for 22.3% of revenue share in 2022, while the ASIC segment held a significant market share of 31.5%.
In contrast to conventional computing systems, embedded platforms have constrained memory, processing power, and energy resources. Therefore, careful consideration of hardware limitations and trade-offs between accuracy and resource utilization are necessary when deploying deep learning algorithms on these platforms.
As part of the deployment, the trained deep learning model is formatted to work with the target embedded platform. This entails optimizing the model for particular hardware accelerators or libraries or converting it to a format specific to a framework.
Furthermore, using hardware acceleration techniques like GPU acceleration, specialized neural network accelerators, or custom hardware designs like FPGAs or ASICs is frequently necessary when deploying deep learning algorithms on embedded platforms. The inference speed and energy efficiency of deep learning algorithms on embedded platforms can be greatly increased by these hardware accelerators. The following are typical examples of deep learning algorithms being deployed on embedded platforms.